In questo articolo vediamo come configurare mongoDB ed installare ElasticSearch per interrogare la nostra base dati in maniera più veloce ed efficiente.
Qualche settimana fa per un progetto a cui stavo lavorando avevo l’esigenza di avere un tempo di risposta basso per le ricerche che effettuavo. Ma con un database di centinaia di milioni di documenti (oltre 500GB) nonostante avessi ottimizzato gli indici di MongoDB non ero riuscito a trovare una configurazione che rispondesse alle mie esigenze, anche per il fatto che erano ricerche su campi testuali.
La soluzione al mio problema è stato quello di utilizzare Elastic Search, un motore di ricerca (basato su Lucene) ottimizzato per ricerche full-text.
Quindi per chi volesse provarlo vi descrivo i passi necessari per farlo.
Configurazione MongoDB
Nel mio caso avevo già installato MongoDB, quindi dovevo solo configurarlo affinchè copiasse in automatico i dati a Elastic Search (ES).
A meno che non vogliamo esportare i dati e quindi importarli in Elastic Search, l’unico modo per connettere MongoDB e ES e utilizzando il sistema di replica di MongoDB.
Configurando mongoDB come un replica set abilitiamo automaticamente il trasferimento dei dati tra i due sistemi di database.
Per farlo è molto semplice, in pratica basta aprire il file di configurazione di mongo “mongod.conf” ed impostare il replica set tramite la riga
|
1 |
replset = rs0 |
quindi riavviare mongo e attivare la replica tramite il comando
|
1 |
rs.inititate() |
per una descrizione più approfondità qui trovate le istruzioni complete : installare replica mongoDB
Se è andata tutto bene, il vostro cursore mongo cambiera in
|
1 |
rs0:PRIMARY> |
|
1 |
Premessa all’installazione di Elastic Search
Prima di procedere dovete fare molta attenzione cone le versioni dei vari componenti. L’integrazione tra MongoDB ed ES avviente tramite un plugin (MongoDB River) che è responsabile del trasferimento dei dati tra i due db.
Se non dovesse funzionare vi troverete il vostro indice in Elastic Search vuoto.
Per assicurarsi di avere la versione corretta utilizzate questa tabella:
River ES MongoDB
master – 1.0.0 – 2.4.9
2.0.0 – 1.0.0 – 2.4.9
1.7.4 – 0.90.10 – 2.4.8
1.7.3 – 0.90.7 – 2.4.8
1.7.2 – 0.90.5 – 2.4.8
1.7.1 – 0.90.5 – 2.4.6
1.7.0 – 0.90.3 – 2.4.5
1.6.11 – 0.90.2 – 2.4.5
1.6.9 – 0.90.1 – 2.4.4
1.6.8 – 0.90.0 – 2.4.3
1.6.7 – 0.90.0 – 2.4.3
1.6.6 – 0.90.0 – 2.4.3
La tabella aggiornata la trovate nella pagina del plugin River di Elastic Search per MongoDB
Nel mio caso avendo installato MongoDB 2.4.8, ho utilizzato le seguenti versioni:
ElasticSearch 0.90.10
Plugin: MongoDb River 1.7.4
Plugin: MapperAttachments 1.90
Plugin: Elasticsearch-head
Installazione Elastic Search e plugin
L’installazione di ES in mac è semplicissimo tramite homebrew:
|
1 |
brew install elasticsearch && brew info elasticsearch |
per altri sistemi è comunque semplice e trovate le istruzioni a questo link :
istruzioni per scaricare ed installare Elastic Search
Per installare i plugin necessari, posizionatevi nella cartella dove è stato installato Elastic Search
(nel mio caso : cd /usr/local/Cellar/elasticsearch/0.90.11) e lanciate:
|
1 |
bin/plugin -install elasticsearch/elasticsearch-mapper-attachments/1.9.0 |
per installare un plugin per gestire la mappatura di attachment di tipi diversi.
|
1 |
bin/plugin --install com.github.richardwilly98.elasticsearch/elasticsearch-river-mongodb/1.7.4 |
per installare il plugin per connettere con MongoDB
|
1 |
bin/plugin -install mobz/elasticsearch-head |
un plugin per accedere a ES tramite un interfaccia web
Ora se tutto è andato bene, avete tutto il necessario per indicizzare i vosti dati con ES.
Lanciate il server con il comando
|
1 |
elasticsearch -f -D es.config=/usr/local/opt/elasticsearch/config/elasticsearch.yml |
e risponderà all’indirizzo di default:
|
1 |
localhost:9200 |
inoltre dato che abbiamo installato il plugin Elasticsearch-head potete aprire il vostro browser all’indirizzo :
|
1 |
http://localhost:9200/_plugin/head |
dove troverete un’interfaccia web con cui potete creare indici, amministrare e creare query di ricerca.
Configurazione Indici River
A questo punto dobbiamo configurare ES affinchè si attivi la connessione con MongoDB e l’organizzazione dei dati per le future interrogazioni.
Questo avviene tramite la creazione dell’indice River.
Per prima cosa eliminiamo quello che ci è stato creato di default dal plugin,
aprite una finestra di terminale e lanciate :
|
1 |
curl -XDELETE localhost:9200/_river |
Se non volete utilizzare il terminale, potete farlo anche tramite l’interfaccia web descritta al paragrafo successivo.
Ora create un nuovo indice river lanciando:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
curl -XPUT "localhost:9200/_river/NOME_INDICE/_meta" -d' { "type": "mongodb", "mongodb": { "db": "NOME_DEL_VOSTRO_DB", "collection": "NOME_DELLA_VOSTRA_COLLECTION" }, "index": { "name": "NOME_INDICE", "type": "NOME_TIPO" } }' |
In NOME_TIPO potete mettere qualsiasi cosa per ora, serve per gestire gli indici con tipo differenti.
Se tutto ok , ottenete dal server una risposta tipo :
|
1 |
{"ok":true,"_index":"_river","_type":"NOME_TIPO","_id":"_meta","_version":1} |
E’ da questo momento in poi, i vostri dati verranno copiati da MongoDB a ElasticSearch indicizzandoli in maniera automatica.
Potete fare una ricerca di esempio col comando:
|
1 |
curl -XGET "http://localhost:9200/finder/_search?q=VOSTRO_CAMPO:STRINGA_DA_CERCARE" |
Query di Ricerche
Per avere informazioni sullo stato di ES :
|
1 |
curl -XGET "http://localhost:9200/_status" |
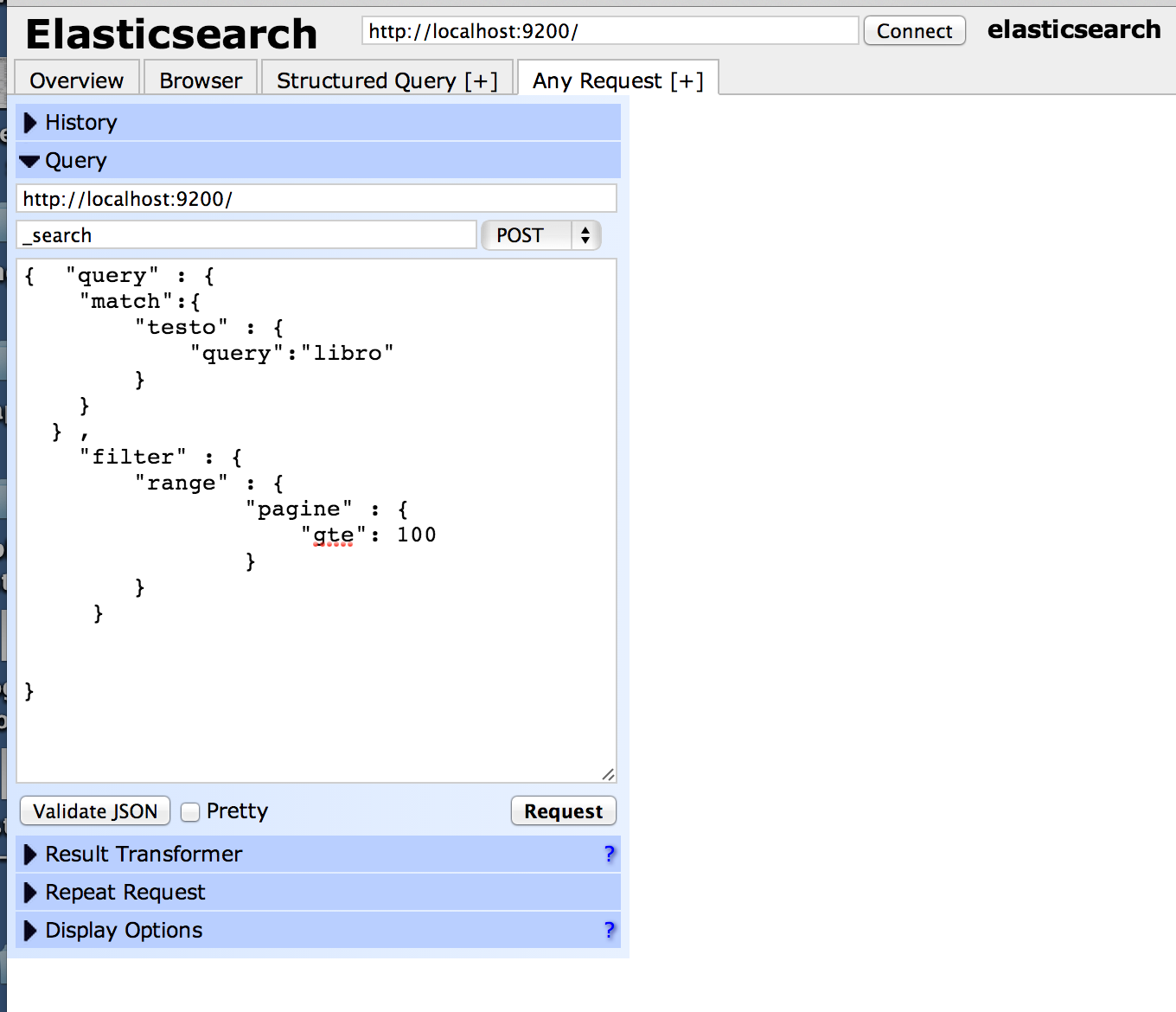
Per fare una ricerca nel campo testo su tutti i libri che hanno più di 100 pagine(quindi nella query seguente si riferiscono ai campi “testo” e “pagine”)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
curl -XGET "http://localhost:9200/finder/_search?" -d' { "query" : { "match":{ "testo" : { "query":"libro" } } } , "filter" : { "range" : { "pagine": { "gte": 100 } } } }' |
Interfaccia Web
All’indirizzo http://localhost:9200/_plugin/head è possibile utilizzare l’interfaccia web del plugin che permette la gestione di ES.
Qui troverete 4 tab :
Overview : Vi mostra un anteprima di tute le funzionalità e la lista degli indici
Browser : Qui trovate tutti i documenti e potete effettuare una ricerca all’interno dei campi
Structured Query : Qui è possibile effettuare ricerche più avanzate sui dati
Any Request : Qui avete il controllo completo, dove potete effettuare richieste REST (POST, GET,DELETE,PUT) complete.
Quindi se volete interrogare ES potete farlo direttamente da qui, scegliendo il metodo (_status,_search, ecc..) , il protocollo ed il documento JSON se necessario.